
Text-to-image generative models can produce photo-realistic images for an extremely broad range of concepts, and their usage has proliferated widely among the general public. On the flip side, these models have numerous drawbacks, including their potential to generate images featuring sexually explicit content, mirror artistic styles without permission, or even hallucinate (or deepfake) the likenesses of celebrities. Consequently, various methods have been proposed in order to "erase" sensitive concepts from text-to-image models. In this work, we examine five recently proposed concept erasure methods, and show that targeted concepts are not fully excised from any of these methods. Specifically, we leverage the existence of special learned word embeddings that can retrieve "erased" concepts from the sanitized models with no alterations to their weights. Our results highlight the brittleness of post hoc concept erasure methods, and call into question their use in the algorithmic toolkit for AI safety.
Warning: Some results may appear offensive to readers.
Over the last 18 months, text-to-image models have garnered significant attention due to their exceptional ability to synthesize high-quality images based on textual prompts. In particular, the open-sourcing of Stable Diffusion has democratized the landscape of image generation technology. This shift underlines the growing potential and practical relevance of these models in diverse real-world applications. However, despite their burgeoning popularity, these models come with serious caveats. They have been shown to produce copyrighted, unauthorized, biased, and potentially unsafe content. This raises serious for the general public whose unfettered use of these tools has opened up the possibility for a wide range of detriments. At one end of the user spectrum, outputs of generative image models can lead to data privacy violations and copyright infringement. On the other end of the user spectrum, uncontrolled outputs of such models can easily result to harmful, offensive, and NSFW content.
The short answer is: sort of.
The long answer is: Not really. The erased models only prevent generation of images with the targeted concepts for certain prompts. In particular, we can learn special word embeddings that can retrieve the so-called "erased" concepts from the sanitized models, and this is done without making any modifications to their existing weights.
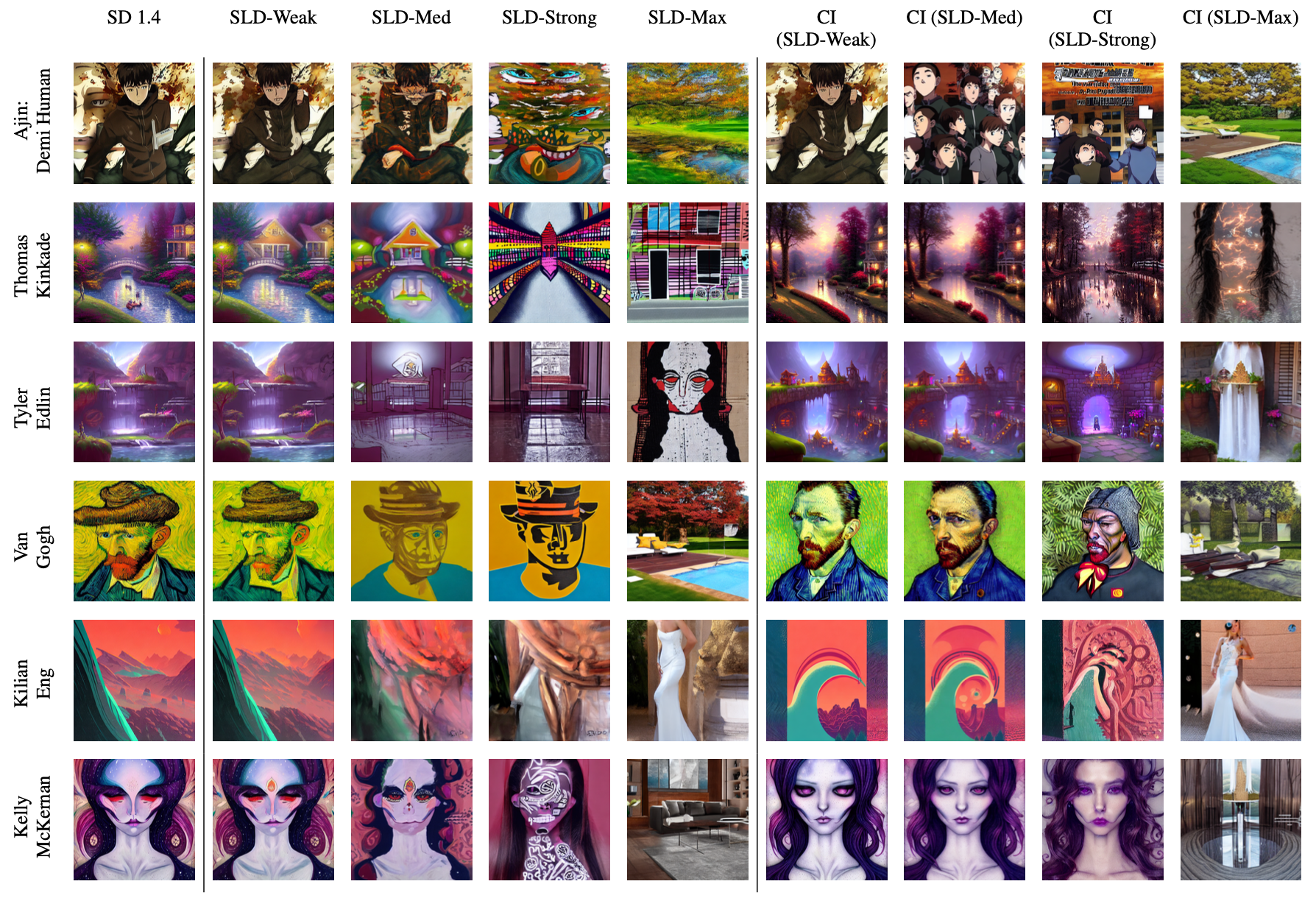
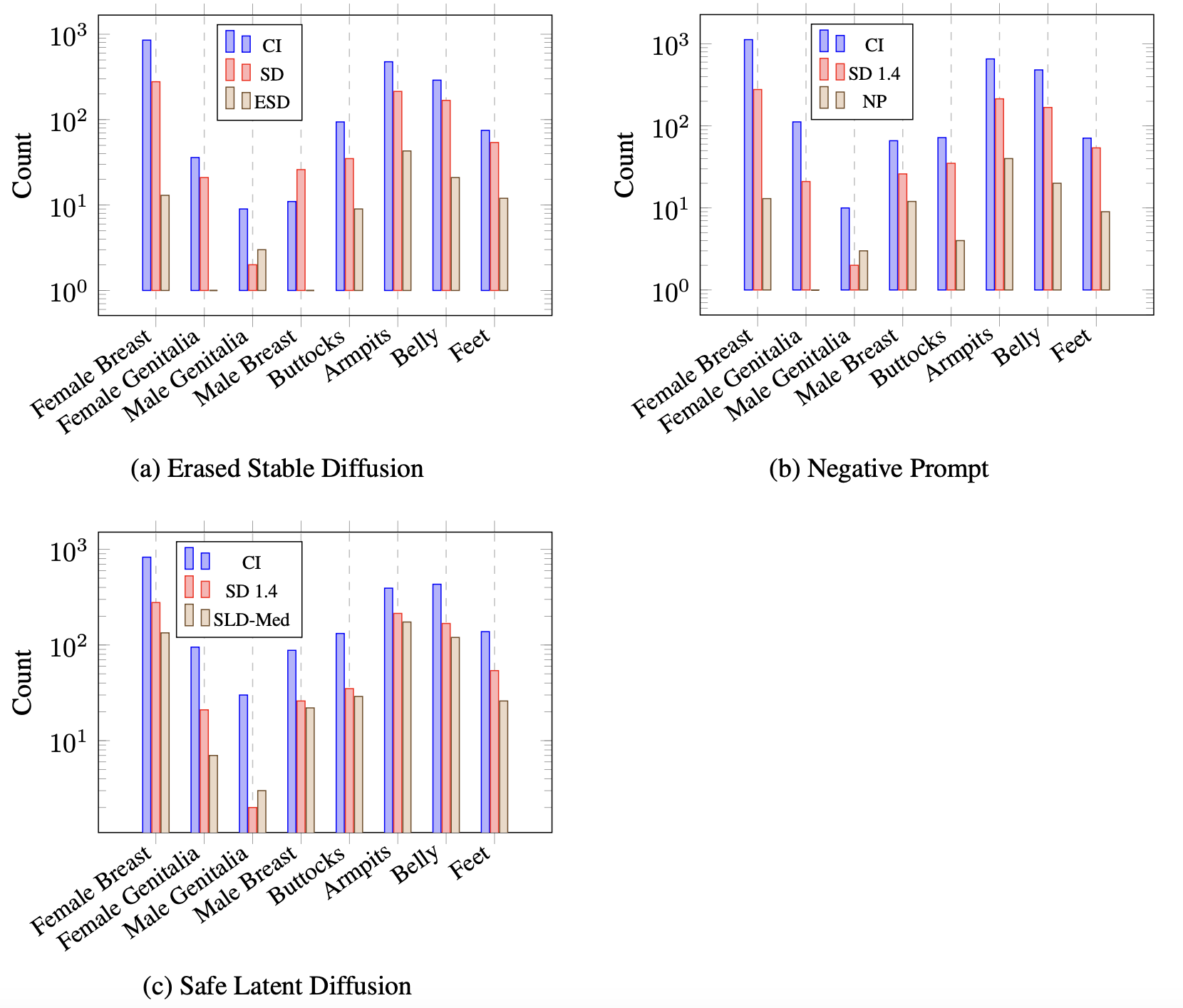
We investigated 5 current concept erasure methods, namely namely Erased Stable Diffusion (ESD), Forget-Me-Not (FMN), Selective Amnesia (SA), Safe Latent Diffusion (SLD), and Negative Prompt (NP). Our results demonstrated our ability to retrieve the "erased" concepts across four distinctive categories: Object, Identity, Art, and NSFW content.



@misc{pham2023circumventing,
title={Circumventing Concept Erasure Methods For Text-to-Image Generative Models},
author={Minh Pham and Kelly O. Marshall and Chinmay Hegde},
year={2023},
eprint={2308.01508},
archivePrefix={arXiv},
primaryClass={cs.LG}
}