
"a knife"
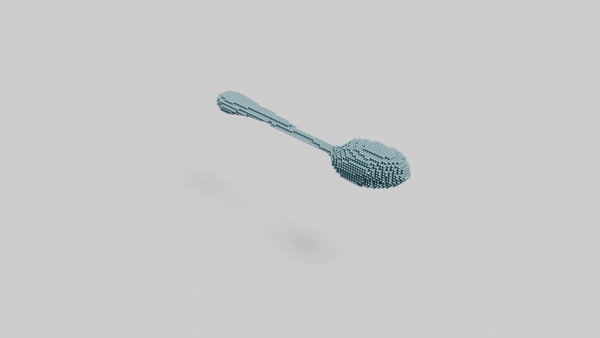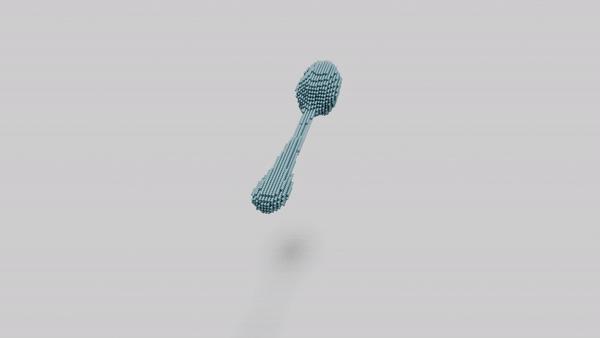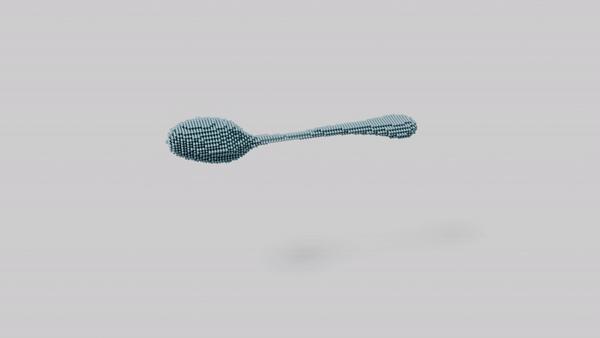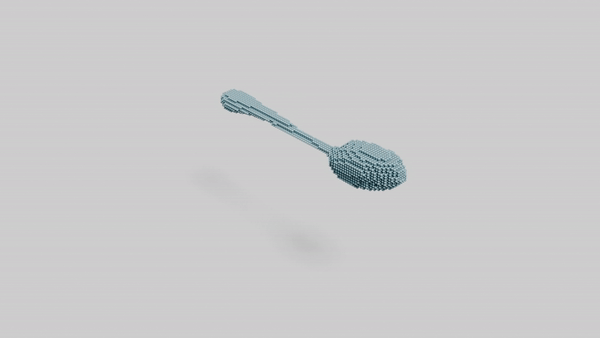
"a spoon"

"a wineglass"

"an umbrella"
Current state-of-the-art methods for text-to-shape generation either require supervised training using a labeled dataset of pre-defined 3D shapes, or perform expensive inference-time optimization of implicit neural representations. In this work, we present ZeroForge, an approach for zero-shot text-to-shape generation that avoids both pitfalls. To achieve open-vocabulary shape generation, we require careful architectural adaptation of existing feed-forward approaches, as well as a combination of data-free CLIP-loss and contrastive losses to avoid mode collapse. Using these techniques, we are able to considerably expand the generative ability of existing feed-forward text-to-shape models such as CLIP-Forge. We support our method via extensive qualitative and quantitative evaluations.
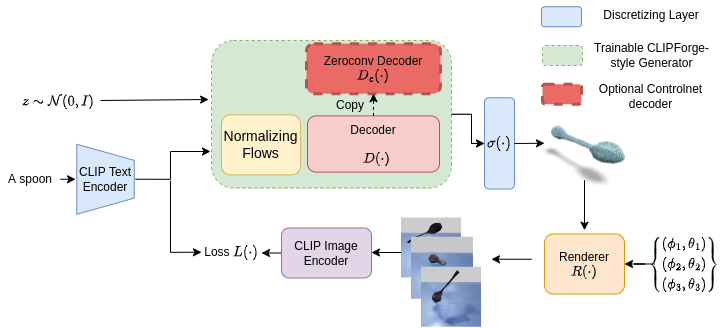
Our method begins by taking a CLIP-Forge architecture which has been pre-trained on the ShapeNet dataset. To introduce novel concepts that we don't have 3D data for, we formulate a training loss that encourages high similarity between the generator's text input and image renderings of the generator's 3D output. This similarity score can be computed as an inner product in CLIP space by using CLIP's frozen image and text encoders. By using a differentiable rendering, we are able to use this metric as a training signal to update CLIP-Forge's weights and expand its generative capabilities.
In addition to this, we also find that there are several other measures which must be taken to achieve good results. To prevent mode collapse, we add an additional contrastive penalty which maintains diversity in outputs across different text queries. One issue that can arise is the forgetting of the original shapes when training on new prompts outside ShapeNet. We address this by augmenting the CLIP-Forge decoder with a locked copy of the original parameters to allow rapid adaptation while preserving existing concepts.
@misc{marshall2023zeroforge,
title={ZeroForge: Feedforward Text-to-Shape Without 3D Supervision},
author={Kelly O. Marshall and Minh Pham and Ameya Joshi and Anushrut Jignasu
and Aditya Balu and Adarsh Krishnamurthy and Chinmay Hegde},
year={2023},
eprint={2306.08183},
archivePrefix={arXiv},
primaryClass={cs.CV}
}